RDF Onboarding
RDF Onboarding¶
Prerequisite:
- Access to a CDF Project.
- Know how to install and setup Python.
- Launch a Python notebook.
In this tutorial we will show how to onboard source data to CDF. We will:
- read in Nordic44 data, containing instances of the nordic power system in the form of RDF triples.
- infer the underlying data model
- prepare data model to be CDF compliant
- upload data model to CDF
- populate data model with instances from the Nordic44 data
from cognite.neat import NeatSession, get_cognite_client
client = get_cognite_client(".env")
Found .env file in repository root. Loaded variables from .env file.
neat = NeatSession(client, storage="oxigraph", verbose=True)
Neat Engine 2.0.3 loaded.
We have already nordic44 as an example in neat and we can read it in as following:
neat.read.examples.nordic44()
No issues found
Let's inspect content of the NEAT session:
neat
Instances
Overview:
- 1 named graphs
- Total of 59 unique types
- 2713 instances in default graph
default graph:
| Type | Occurrence | |
|---|---|---|
| 0 | CurrentLimit | 530 |
| 1 | Terminal | 452 |
| 2 | OperationalLimitSet | 238 |
| 3 | OperatingShare | 207 |
| 4 | VoltageLimit | 184 |
| ... | ... | ... |
| 58 | FullModel | 1 |
Provenance:
- Initialize graph store as OxigraphStore
- Extracted triples to named graph urn:x-rdflib:default using RdfFileExtractor
Neat provides you a way also to visualize instances:
neat.show.instances()
instances.html
Let's now infer data model from the instances (this take with in-memory graph store ~ 20s).
The inference will produce un-validated logical data model (aka Information Rules), which we will later prepare for validation and later conversion to physical data model (aka DMS Rules)
neat.infer()
| count | |
|---|---|
| NeatIssue | |
| ResourceRegexViolationWarning | 333 |
Now if we inspect session you will beside instances overview also metadata about the inferred data model:
neat
Data Model
| type | Logical Data Model |
|---|---|
| intended for | Information Architect |
| name | Inferred Model |
| external_id | NeatInferredDataModel |
| version | v1 |
| classes | 59 |
| properties | 333 |
Instances
Overview:
- 1 named graphs
- Total of 59 unique types
- 2713 instances in default graph
default graph:
| Type | Occurrence | |
|---|---|---|
| 0 | CurrentLimit | 530 |
| 1 | Terminal | 452 |
| 2 | OperationalLimitSet | 238 |
| 3 | OperatingShare | 207 |
| 4 | VoltageLimit | 184 |
| ... | ... | ... |
| 58 | FullModel | 1 |
Provenance:
- Initialize graph store as OxigraphStore
- Extracted triples to named graph urn:x-rdflib:default using RdfFileExtractor
Since the inferred data model might contain external_ids of properties and objects which are not compliant with cdf we need to prepare it prior validation and conversion to cdf compliant data model. This can be done by running:
neat.fix.data_model.cdf_compliant_external_ids()
Success: NEAT(verified,logical,neat_space,NeatInferredDataModel,v1) → NEAT(verified,logical,neat_space,NeatInferredDataModel,v1)
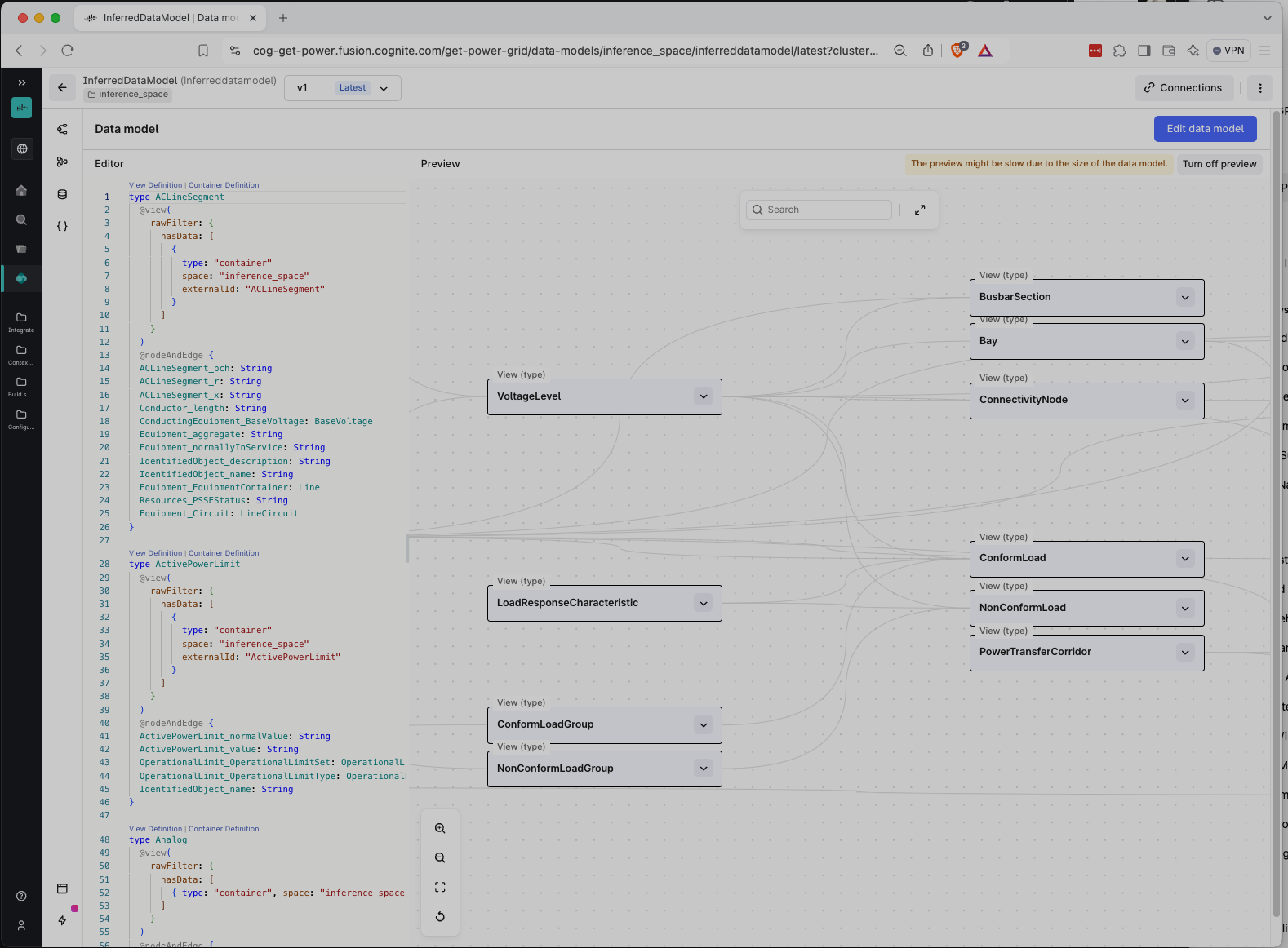
Now let's convert the data model to be CDF complian data model (aka physical data model)
neat.convert()
Rules converted to dms.
Success: NEAT(verified,logical,neat_space,NeatInferredDataModel,v1) → NEAT(verified,physical,neat_space,NeatInferredDataModel,v1)
neat
Data Model
| aspect | physical |
|---|---|
| intended for | DMS Architect |
| name | Inferred Model |
| space | neat_space |
| external_id | NeatInferredDataModel |
| version | v1 |
| views | 59 |
| containers | 59 |
| properties | 333 |
Instances
Overview:
- 1 named graphs
- Total of 59 unique types
- 2713 instances in default graph
default graph:
| Type | Occurrence | |
|---|---|---|
| 0 | CurrentLimit | 530 |
| 1 | Terminal | 452 |
| 2 | OperationalLimitSet | 238 |
| 3 | OperatingShare | 207 |
| 4 | VoltageLimit | 184 |
| ... | ... | ... |
| 58 | FullModel | 1 |
Provenance:
- Initialize graph store as OxigraphStore
- Extracted triples to named graph urn:x-rdflib:default using RdfFileExtractor
- Added dict to urn:x-rdflib:default named graph
- Upsert prefixes to the name graph {named_graph}
- Added dict to urn:x-rdflib:default named graph
- Upsert prefixes to the name graph {named_graph}
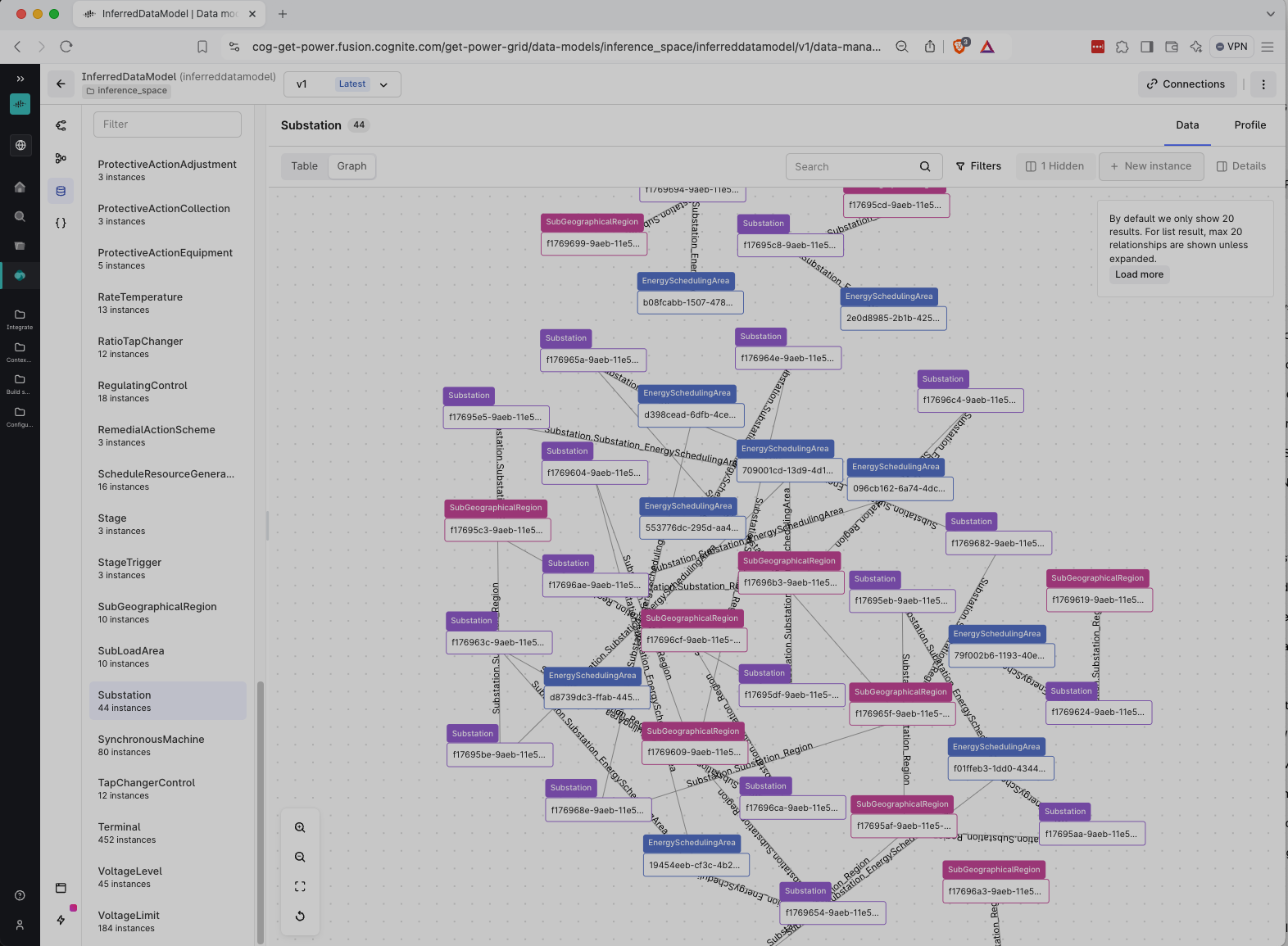
Now we have all the components to form knowledge graph in CDF, i.e. data model and instances. Let's upload them to CDF:
neat.to.cdf.data_model()
| name | created | |
|---|---|---|
| 0 | spaces | 1 |
| 1 | containers | 59 |
| 2 | views | 59 |
| 3 | data_models | 1 |
neat.to.cdf.instances(space="inference_space")
| name | created | changed | |
|---|---|---|---|
| 0 | Nodes | 1000.0 | NaN |
| 1 | Edges | NaN | NaN |
| 2 | Nodes | 737.0 | 263.0 |
| 3 | Edges | NaN | NaN |
| 4 | Nodes | 547.0 | 166.0 |
| 5 | Edges | NaN | NaN |
Results of the upload should be visible in the CDF project such as in the following screenshot: